
Web kazıma işleminde kullanılacak doğru seçicinin hangisi olduğunu biliyor musunuz? Web kazıma, internetten veri elde etmek için son on yılda oldukça popüler olmuştur. İşletmelerin daha iyi iş kararları almak için veri elde etmelerine ve analiz etmelerine yardımcı olur. Otomatikleştirilmiş teknolojiler sayesinde web kazıma hiç bu kadar kolay olmamıştı.
Web kazıma işleminde kullanılacak doğru seçicinin hangisi olduğunu biliyor musunuz? Web kazıma, internetten veri elde etmek için son on yılda oldukça popüler olmuştur. İşletmelerin daha iyi iş kararları almak için veri elde etmelerine ve analiz etmelerine yardımcı olur. Otomatikleştirilmiş teknolojiler sayesinde web kazıma hiç bu kadar kolay olmamıştı.
Bununla birlikte, seçtiğiniz araç veya çerçeve ne olursa olsun, kazıyıcınızın verileri kibarca kazımasını sağlamak için çok önemli bir karar vermelisiniz. Bu, bu makalede öğreneceğiniz XPath veya CSS seçicileri kullanarak web öğelerini ayıklayıp ayıklamayacağınızdır.
Bazı mevcut örneklerle konuya girelim.
XPath, XML Yol Dili anlamına gelir. Ancak, web kazıma işleminde olduğu gibi, bir XML belgesinden veya HTML'den etiketleri veya etiket gruplarını seçmek için XML olmayan sözdizimi kullanır. XPath, HTML ağacının tamamını dolaşmadan bir HTML veya XML öğesine doğrudan erişmek için ifadeler yazmanıza olanak tanır.
XPath kullanarak bir öğeye nasıl erişebileceğinizi anlamak için, bir HTML kodu ile daha derine inelim. Bazı temel HTML'leri zaten bildiğinizi varsayıyorum.
<!doctype html>
<html xmlns=”http://www.w3.org/1999/xhtml” lang="en" xml:lang="en">
<head>
<meta charset="utf-8">
<title>Awesome Products at your Fingertips</title>
</head>
<body>
<h1>Description of product features</h1>
<p>These products are great. So let's just look at the features !</p>
<ul id="product-list" class=”basic-list”>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</body>
</html>
Yukarıdaki kodu istediğiniz bir editörde yazabilir ve products.html olarak kaydedebilirsiniz. Daha sonra bunu bir tarayıcıda görüntüleyebilirsiniz (bu örnek üzerinden onunla yürüyeceğimiz için tercihen Google Chrome).
Tarayıcı bu kodu çalıştırdığında, HTML'yi ifade eder ve öğelerin bir ağaç gösterimini oluşturur. Aşağıdaki biçimde DOM (Document Object Model) olarak bilinir:

Verilen bağlantıdan DOM hakkında daha fazla bilgi edinebilirsiniz. Şimdi burada odak noktamız, tüm ağacı dolaşmadan bu öğelerin her birine doğrudan nasıl gidileceğine ilişkin XPath. Öyleyse Xpath'in temel terminolojisi ile başlayalım.
XPath ile en temel öğe bir düğümdür. Düğümler, az önce DOM ağacında gördüğünüz tek tek öğelerdir. Bu makalede ilerledikçe, düğümlerin etiket öğelerinden, niteliklerden, kendisine atanan dizgi değerlerinden ve benzerlerinden oluştuğunu daha da keşfedeceksiniz. Her XML veya HTML sayfasında yedi adet düğüm vardır ve şimdi her bir düğüm türüne yakından bakalım.
Yukarıdaki üç tanesi en önemlileri olsa da, bilgi olması açısından aşağıdaki dört tanesini bilmek de hayati önem taşımaktadır.
Bunu yapmanın iki yolu vardır. İlk olarak, bunu gösterelim veya bir örnek kodlayalım. Yukarıda da belirttiğim gibi, umarım yerel diskinize kaydetmişsinizdir ve tarayıcınızda görüntülenmeye hazırdır.
Sayfa yüklendiğinde, farenizi 1. öğenin üzerine getirin ve sağ tıklayın. Ardından aşağıdaki ekran görüntüsünde gösterildiği gibi görünen menü öğelerinden İncele'yi seçin:
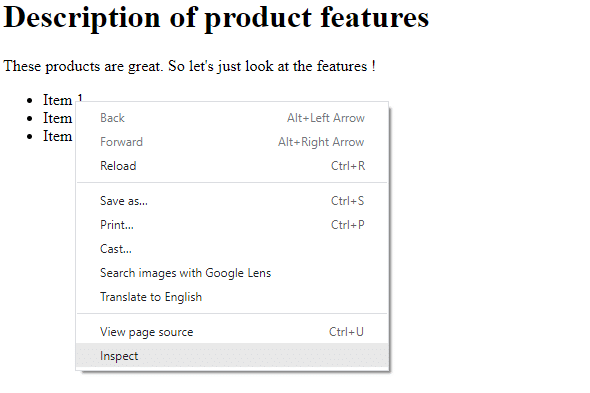
Then you would be able to find the full XPath by clicking on the <li> element in the console and selecting “copy” from the drop-down menu, and then specifying “Copy full XPath as shown below:
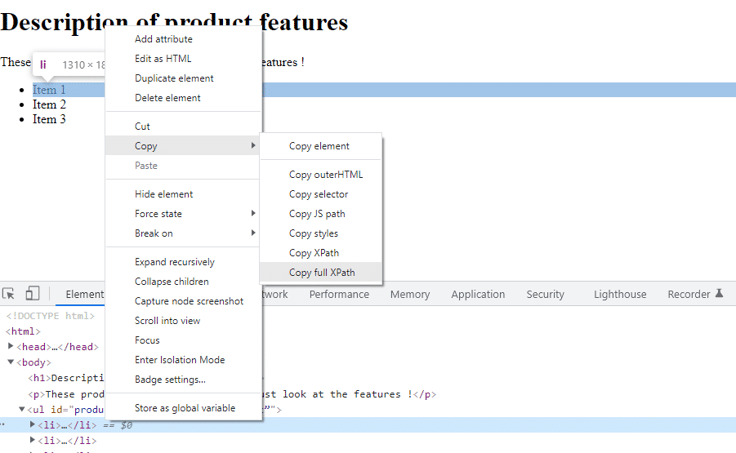
Sonra bunu bir metin dosyasına veya bir yere yapıştırdıktan sonra şunu elde edersiniz:
/html/body/ul/li[1]Bu mutlak yol olarak bilinir. Bunu nasıl türettiğinizi aşağıda açıklayacağım.
Adım 1 => li[1] //Burada bir, ilk li öğesini belirtir
Adım 2 => /li[1]
Adım 3 => ul/li[1]
Adım 4 => /ul/li[1]
Adım 5 => body/ul/li[1]
Adım 6 => /body/ul/li[1]
Adım 7 => html/body/ul/li[1]
Adım 8 => /html/body/ul/li[1]
With this method, you need to work your way backward, starting from the target element all the way back to the root element. You add a forward slash before the element you have just added as you write each element. So let’s look at how you could work out the XPath for the first <li> element manually:
Yukarıdaki yöntem uzun gibi görünse de, tam XPath'in nasıl oluşturulacağını anlamanıza yardımcı olacaktır. Şimdi göreceli yönteme geçelim.
//*[@id="product-list"]/li[1]As you can see, it is pretty short, and the path is relative to the parent <ul> element. Since the <li> element does not have an id attribute, its relative path is relative to the <ul> element.
Önemli farklar, tam XPath'in okunabilir olmaması ve bakımının zor olmasıdır. Diğer bariz endişe ise kök elemandan başlayarak herhangi bir elemanda değişiklik olması durumunda mutlak XPath'in geçerli olmayacağıdır. Bu yüzden göreceli XPath kullanmak mantıklıdır.
Ancak, bu konuda daha fazla yorum yapmadan önce, ilk olarak avantaj ve dezavantajlara bakalım.
XPath ile, bir öğenin adını bilmiyorsanız endişelenmenize gerek yoktur, çünkü olası eşleşmeleri aramak için contains işlevini kullanabilirsiniz. Bu nedenle, kazınacak öğeleri sorgularken DOM'da yukarı doğru gidebilirsiniz.
CSS'nin bir diğer önemli avantajı da Internet Explorer'ın eski sürümleri gibi eski tarayıcılarda çalışmasıdır.
Yukarıda öğrendiğiniz gibi, en önemli dezavantajı, yoldaki öğeleri değiştirdiğinizde kırılmasının daha kolay olmasıdır. Aşağıda bulacağınız CSS seçicilerine kıyasla anlaşılması zor olabilir.
Ayrıca, XPath'ten öğeleri alırken, performansı CSS'den oldukça yavaştır.
Bildiğiniz gibi CSS, bir web sayfasındaki HTML öğelerini şekillendirmede belirgin bir şekilde kullanılan Basamaklı Stil Sayfaları anlamına gelir. Bu stiller yazı tipinize, arka plan resimlerinize ve renklerinize renk uygulamayı, öğeleri hizalamayı ve konumlandırmayı ve paragraflar arasındaki boşlukları artırmayı/azaltmayı içerir.
Bir HTML öğesine bir stil ayarlamak için, bunu bir CSS Seçici aracılığıyla belirtmeniz gerekir. Bir sonraki bölümdeki biçimlendirmeyle başlayan basit bir örnekle başlayalım.
<h1 id="main-heading" class="header-styles" name="h1name">What are CSS Selectors?</h1>İşte yukarıdaki öğe için CSS seçici:
Bunları birleştirebilirsiniz de:
h1.header-styles-BuCSS seçici, header-styles sınıfına sahip h1 öğelerini seçer.
Çocukları seçmek için > operatörü kullanılır. Buna karşılık, + işleci ilk kardeşi seçer ve ~ işleci tüm kardeşleri seçmek için kullanılır. Birkaç örnek aşağıdaki gibidir:
Beautiful Soup 'un desteklemediği XPath'in aksine, CSS seçicileri en etkili kazıma kütüphaneleri tarafından desteklenmektedir. Ayrıca, XPath'in aksine, CSS seçicilerinin öğrenilmesi ve bakımı daha kolaydır. Internet Explorer sürüm 8'in altındaki eski tarayıcılar dışında neredeyse tüm tarayıcılar desteklemektedir. Ancak, günümüzde insanlar bu tarayıcıları nadiren kullanmaktadır.
Internet Explorer'ın eski sürümlerini denklemden çıkarsanız bile, farklı tarayıcılarda nasıl işlendikleri konusunda hala tutarsızlıklar olabilir.
Çeşitli CSS sürümleri olduğundan, hem geliştiriciler hem de yeni başlayanlar arasında kafa karışıklığı yaratabilirler.
Günümüz web teknolojisindeki bir diğer hayati faktör de CSS'nin güvenliğidir.

XPath ve CSS arasındaki belirgin fark XPath'in çift yönlü olmasıdır. Bu, DOM ağacında her iki yönde de gezinebileceğiniz anlamına gelir. Ancak, tek yönlü akış olarak bilinen CSS ile yalnızca üst düğümden alt düğümlere geçebilirsiniz.
Önceki bölümlerde tartışıldığı gibi, XPath'in bakımı daha zordur ve etkili okunabilirlik için iyi bir aday değildir. Öte yandan, XPath eski tarayıcılarda çalışabilse de, render şekli bir tarayıcıdan diğerine farklılık gösterir.
Dolayısıyla bu konuda CSS'nin üstünlüğü vardır.
XPATH, CSS'in yalnızca DOM ağacını yukarı doğru kat etmek gibi belirli alanlarda ebeveynlerden çocuğa geçebilmesiyle öne çıkmaktadır. Hız söz konusu olduğunda, CSS'in üstünlüğü vardır.
Ancak, web kazıma söz konusu olduğunda XPath ve CSS arasındaki hız farkı çok önemli değildir. Web kazıma işleminde ağ gecikmesi gibi dikkate alınması gereken başka faktörler de vardır.
XPath'i desteklemediği için Beautiful Soup söz konusu olduğunda CSS ilk tercihiniz olacaktır.
Web kazıma projeniz için hangi seçicileri kullanmanız gerektiği konusunda kesin bir cevap yoktur. Bu makalede keşfettiğiniz gibi, XPath bazı durumlarda üstünlük sağlarken, CSS diğerlerinde öne çıkmaktadır.
Bu nedenle, geçiş, tarayıcı desteği ve tartıştığımız bazı teknik özellikler gibi belirli hayati noktaları hesaba katmanız gerekir. Öğrendiklerinizi uygulayacağınızı ve daha fazla makale için bizi izlemeye devam edeceğinizi umuyoruz.