
People can easily gather and scrape information from multiple sources such as Facebook, Reddit, and Twitter. You can think of a scraper as a specialized tool that extracts data from a web page accurately and quickly. The scraping APIs help the scrapers avoid getting banned by anti-scraping techniques that the websites place. However, it is
İnsanlar Facebook, Reddit ve Twitter gibi birden fazla kaynaktan kolayca bilgi toplayabilir ve kazıyabilir. Bir kazıyıcıyı, bir web sayfasından doğru ve hızlı bir şekilde veri çıkaran özel bir araç olarak düşünebilirsiniz. Kazıma API'leri, kazıyıcıların web sitelerinin yerleştirdiği kazıma karşıtı teknikler tarafından yasaklanmasını önlemeye yardımcı olur. Ancak API'leri kullanmak, kendi yönettiğiniz bir proxy aracına kıyasla pahalıdır.
Reddit'i kullandınız mı? Eğer bir sosyal araştırmacıysanız ve internette çok zaman geçiriyorsanız, Reddit'i duymuş olma ihtimaliniz yüksektir. Reddit kendisini "internetin ön sayfası" olarak tanımlıyor. İnsanların içerik ve haber paylaştığı ya da başkalarının gönderilerine yorum yaptığı çevrimiçi bir tartışma forumudur. Dolayısıyla, İnternet pazarlamacıları ve sosyal araştırmacılar için inanılmaz bir veri kaynağıdır.
Reddit, verileri taramak için PRAW için kısaltılmış Python Reddit API Wrapper adlı bir API'ye sahiptir. Bu blogda, size python kullanarak Reddit'i nasıl kazıyacağınıza dair adımları göstereceğim. Ancak bundan önce, Reddit'i neden kazımanız gerektiğini bilmeniz gerekir.
Reddit'in tasarımı hakkında konuşursak, "subreddit" olarak bilinen çeşitli topluluklara ayrılmıştır. İlgilendiğiniz konuyla ilgili herhangi bir alt dizini internette bulabilirsiniz. Sosyal araştırmacılar, belirli bir konu için Reddit tartışmalarını çıkardıklarında analiz yapar, çıkarımlarda bulunur ve eyleme geçirilebilir planlar uygular.
Reddit'ten aşağıdaki gibi birçok veri noktasını kazıyabilirsiniz:
Aşağıdaki ihtiyaçlar nedeniyle Reddit'ten işinizle ilgili herhangi bir bilgiyi kazıyabilirsiniz:

Mesela,
Reddit kazıma, Reddit web sitesinden halka açık verileri çıkarmak için web kazıyıcıları (bilgisayar programları) kullanır. Resmi Reddit API'sini kullanırken karşılaşacağınız sınırlamalar nedeniyle Reddit kazıyıcılarını kullanmanız gerekir. Bununla birlikte, Reddit'ten veri çıkarmak için Reddit API'sini kullanmayan web kazıyıcı kullanırsanız, Reddit kullanım koşullarını ihlal etmiş olursunuz. Ancak bu, web kazımanın yasa dışı olduğu anlamına gelmez.
Sorunsuz bir kazıma oturumu geçirmek için Reddit tarafından uygulanan kazıma önleyici sistemlerden kaçınmanız gerekecektir. Reddit tarafından kullanılan en yaygın kazıma önleme teknikleri şunlardır:
IP takibi sorununu proxyler ve IP rotasyonu yardımıyla çözebilirsiniz. Captcha sorununu ise 2Captcha gibi Captcha çözücüleri kullanarak çözebilirsiniz.

Reddit'i kazımanın beş yolu vardır ve bunlar:
Aşağıdaki adımların yardımıyla Reddit API'sini kullanarak Reddit'i nasıl kazıyabileceğimizi görelim.
İlerlemeden önce bir Reddit hesabı oluşturmanız gerekir. PRAW'ı kullanmak için bu bağlantıyı takip ederek Reddit API'sine kaydolmalısınız.
İlk olarak, Pandas'ın yerleşik modüllerini, yani datetime'ı ve iki üçüncü taraf modülü olan PRAW ve Pandas'ı aşağıda gösterildiği gibi içe aktaracağız:
import praw
import pandas as pd
import datetime as dtPython Reddit API Wrapper anlamına gelen Praw'ı kullanarak Reddit verilerine erişebilirsiniz. İlk olarak, praw.Reddit fonksiyonunu çağırarak ve bir değişkende saklayarak Reddit'e bağlanmanız gerekir. Daha sonra, aşağıdaki argümanları fonksiyona aktarmanız gerekir.
reddit = praw.Reddit(client_id='PERSONAL_USE_SCRIPT_14_CHARS', \
client_secret='SECRET_KEY_27_CHARS ', \
user_agent='YOUR_APP_NAME', \
username='YOUR_REDDIT_USER_NAME', \
password='YOUR_REDDIT_LOGIN_PASSWORD')Şimdi, seçtiğiniz subreddit'i alabilirsiniz. Yani, reddit'ten (değişken) .subreddit örneğini çağırın ve erişmek istediğiniz subreddit'in adını iletin. Örneğin, r/Nootropics alt dizinini kullanabilirsiniz.
subreddit = reddit.subreddit('Nootropics')Her subreddit, Redditçiler tarafından oluşturulan konuları organize etmek için aşağıdaki beş farklı yola sahiptir:
En çok oy alan konuları şu şekilde yakalayabilirsiniz:
top_subreddit = subreddit.top()r/Nootropics'teki en iyi 100 gönderimi içeren liste benzeri bir nesne elde edeceksiniz. Bununla birlikte, Reddit'in istek sınırı 1000'dir, bu nedenle .top as'a bir sınır geçerek örnek boyutunu kontrol edebilirsiniz:
top_subreddit = subreddit.top(limit=600)İstediğiniz herhangi bir veriyi kazıyabilirsiniz. Ancak biz konularla ilgili aşağıdaki bilgileri kazıyacağız:
Bunu, verilerimizi bir sözlükte depolayarak ve ardından aşağıda gösterildiği gibi bir for döngüsü kullanarak yapacağız.
topics_dict = { "title":[], \
"score":[], \
"id":[], "url":[], \
"created": [], \
"body":[]}Şimdi, Reddit API'sinden verileri kazıyabiliriz. Bilgileri top_subreddit nesnemiz üzerinden yineleyerek sözlüğümüze ekleyeceğiz.
for submission in top_subreddit:
topics_dict["id"].append(submission.id)
topics_dict["title"].append(submission.title)
topics_dict["score"].append(submission.score)
topics_dict["created"].append(submission.created)
topics_dict["body"].append(submission.selftext)Şimdi, Python sözlüklerinin okunması kolay olmadığı için verilerimizi Pandas Dataframe'lerine koyuyoruz.
topics_data = pd.DataFrame(topics_dict)Pandas'ta çeşitli formatlarda veri dosyaları oluşturmak çok kolaydır, bu nedenle verilerimizi bir CSV dosyasına aktarmak için aşağıdaki kod satırlarını kullanıyoruz.
topics_data.to_csv('FILENAME.csv', index=False)Proxy kullanım kısıtlamaları söz konusu olduğunda Reddit'in çok katı bir web sitesi olmadığını biliyorsunuz. Ancak Reddit'teki işlemlerinizi proxy kullanmadan otomatikleştirirseniz yakalanabilir ve cezalandırılabilirsiniz.
Şimdi, Reddit için iki kategoriye ayrılan en iyi proxy'lerden bazılarına bakalım:
Konut Proxy'leri - Bunlar, İnternet Servis Sağlayıcısının (İSS) belirli bir fiziksel konumdaki bir cihaza atadığı IP adresleridir. Bu proxy'ler, kullanıcının bir web sitesine giriş yapmak için kullandığı cihazın gerçek konumunu ortaya çıkarır.
Veri merkezi proxy'leri - Bunlar, herhangi bir İnternet Hizmet Sağlayıcısından kaynaklanmayan çeşitli IP adresleridir. Bunları bir bulut hizmet sağlayıcısından alıyoruz.
Aşağıda Reddit için en iyi konut ve veri merkezi proxy'lerinden bazıları yer almaktadır.
Smartproxy, Reddit otomasyonu için etkili olduğu için en iyi premium konut proxy sağlayıcılarından biridir. Geniş bir IP havuzuna sahiptir ve hizmetine abone olduğunuzda tüm IP'lere erişim sağlar.

Stormproxy 'lerin fiyatlandırması ve sınırsız bant genişliği onları iyi bir seçim haline getirmektedir. Uygun fiyatlı ve kullanımı ucuzdur. Çeşitli kullanım durumları için proxy'leri var ve Reddit otomasyonu için en iyi konut proxy'lerini sağlıyorlar.

ProxyScrape kazıma için proxyler sunmaya odaklanan popüler proxy hizmet sağlayıcılarından biridir. Paylaşılan veri merkezi proxy'lerinin yanı sıra özel veri merkezi proxy'leri de sunar. İnternetteki web sitelerinden veri kazımak için kullanabileceğiniz 40 binden fazla veri merkezi proxy'sine sahiptir.
ProxyScrape kullanıcılarına üç tür hizmet sunmaktadır,
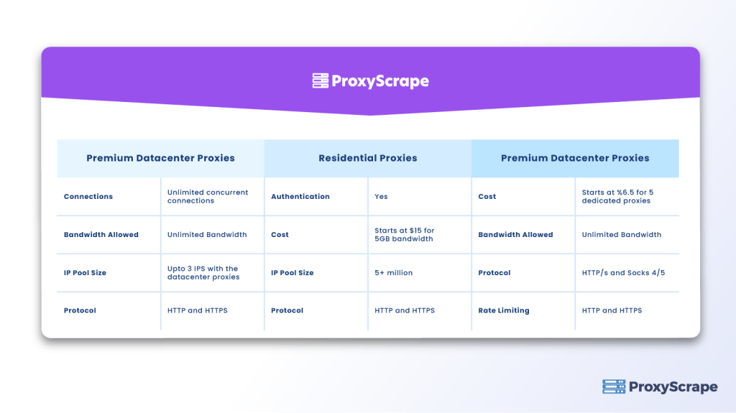
Highproxies Reddit ile çalışır ve aşağıdaki proxy kategorilerine sahiptir:

Instantproxies 'i Reddit otomasyonu için de kullanabilirsiniz çünkü çok güvenli, güvenilir, hızlı ve yaklaşık yüzde 99,9 çalışma süresine sahiptirler. Tüm veri merkezi proxy'leri arasında en ucuz olanıdır.

Reddit'te bazı otomatik araçlarla çalışırken proxy'lere ihtiyacınız vardır. Bunun nedeni, Reddit'in otomatik eylemleri kolayca algılayan ve IP'nizin platforma erişimini engelleyen çok hassas bir web sitesi olmasıdır. Dolayısıyla, oylar, gönderiler, gruplara katılma/ayrılma ve birden fazla hesabı yönetme gibi bazı görevleri otomatikleştiriyorsanız, kötü sonuçlardan kaçınmak için kesinlikle proxy kullanmanız gerekir.
Reddit kazıma gereksinimleriniz küçükse manuel kazıma yöntemini tercih edebilirsiniz. Ancak gereksinimler artarsa, web kazıma araçları ve özel komut dosyaları gibi otomatik kazıma metodolojilerinden yararlanmanız gerekir. Web kazıyıcılar, günlük kazıma gereksinimleriniz birkaç milyon gönderi içinde olduğunda maliyet ve kaynak açısından verimli olduğunu kanıtlar.
Öyleyse, büyük miktarda Reddit verisini kazımak için en iyi çözüm olarak en iyi Reddit kazıyıcılarından bazılarına bakalım.
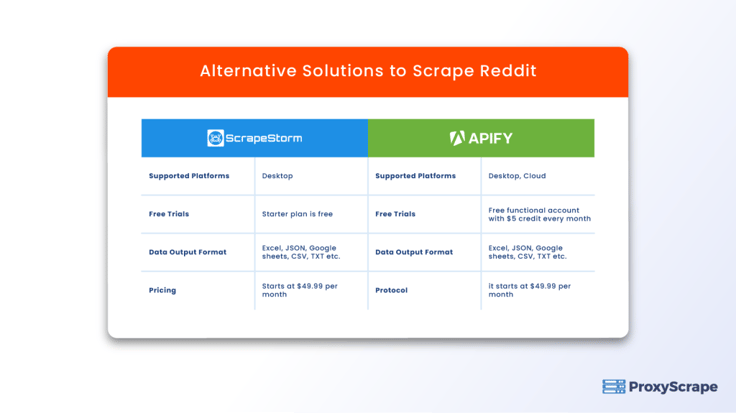
Scrapestorm, Reddit'i kazımak söz konusu olduğunda oldukça iyi çalıştığı için piyasada bulunan en iyi kazıma araçlarından biridir. Web sayfasındaki önemli veri noktalarını otomatik olarak tanımlamak için yapay zekadan yararlanır.
Apify'ın Reddit kazıyıcısı, Reddit API'sini kullanmadan veri çıkarmanızı kolaylaştırır. Bu, ticari kullanım için verileri indirmek için bir geliştirici API belirtecine ve Reddit'ten yetkilendirmeye ihtiyacınız olmadığı anlamına gelir. Ayrıca Apify platformunun entegre proxy hizmetini kullanarak kazıma işleminizi optimize edebilirsiniz.
Reddit verilerini kazımanın beş yolunu tartıştık ve en kolayı Reddit API kullanmaktır çünkü yalnızca temel kodlama becerileri gerektirir. PRAW, Reddit API için temiz bir Python arayüzü ile bir Reddit API kullanmanızı sağlayan bir Python sarmalayıcıdır. Ancak büyük Reddit kazıma gereksinimleriniz olduğunda, Reddit kazıyıcılarının yardımıyla Reddit web sitesinden halka açık verileri çıkarabilirsiniz. Reddit web sitesindeki eylemlerinizi otomatikleştirmek için bir veri merkezi veya yerleşim proxy'leri kullanmanız gerekir.