
Web scraping is the art of extracting data from the internet and using it for meaningful purposes. It is also sometimes known as web data extraction or web data harvesting. For newbies, it is just the same as copying data from the internet and storing it locally. However, it is a manual process. Web scraping
Web kazıma, internetten veri çıkarma ve bunları anlamlı amaçlar için kullanma sanatıdır. Bazen web verisi çıkarma veya web verisi toplama olarak da bilinir. Yeni başlayanlar için, internetten veri kopyalamak ve yerel olarak depolamakla aynı şeydir. Ancak bu manuel bir süreçtir. Web kazıma, web tarayıcılarının yardımıyla çalışan otomatik bir süreçtir. Web tarayıcıları HTTP protokolünü kullanarak internete bağlanır ve kullanıcının otomatik bir şekilde veri almasını sağlar. İnterneti zenginleştirilmiş toprak, verileri de yeni yağ olarak düşünebiliriz; web kazıma ise bu yağı çıkarmak için kullanılan bir tekniktir.
İnternetten veri kazıma ve analiz etme yeteneği, ister veri bilimci, ister mühendis, ister pazarlamacı olun, önemli bir teknik haline gelmiştir. Web kazımanın büyük ölçüde yardımcı olabileceği çeşitli kullanım durumları olabilir. Bu makalede, Python kullanarak Amazon'dan veri kazıyacağız. Son olarak, kazınan verileri analiz edeceğiz ve bunun normal bir kişi, veri bilimcisi veya bir e-ticaret mağazası işleten kişi için ne kadar önemli olduğunu göreceğiz.
Sadece küçük bir önlem: Python ve web kazıma konusunda yeniyseniz, bu makaleyi anlamak sizin için biraz daha zor olabilir. Giriş seviyesindeki makalelere göz atmanızı tavsiye ederim ProxyScrape ve sonra buna gel.
Kod ile başlayalım.
Öncelikle kod için gerekli olan tüm kütüphaneleri içe aktaracağız. Bu kütüphaneler verileri kazımak ve görselleştirmek için kullanılacak. Her birinin ayrıntılarını öğrenmek istiyorsanız, resmi belgelerini ziyaret edebilirsiniz.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
matplotlib satır içi
yenideniçe aktar
İçe aktar ma süresi
from datetime import datetime
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
from urllib.request import urlopen
from bs4 import BeautifulSoup
i̇thalat talepleri̇Şimdi Amazon'un en çok satan kitaplarından faydalı bilgileri kazıyacağız. Kazıyacağımız URL şu şekildedir:
https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_’+str(pageNo)+’?ie=UTF8&pg=’+str(pageNo)
Tüm sayfalara erişmemiz gerektiğinden, gerekli veri kümesini almak için her sayfada döngü yapacağız.
URL'ye bağlanmak ve HTML içeriğini almak için aşağıdakiler gereklidir,
Önemli verilerimizin altında yer alacağı önemli etiketlerden bazıları şunlardır,
Verilen sayfayı incelerseniz, üst etiketi ve ona karşılık gelen öğeleri görürsünüz.
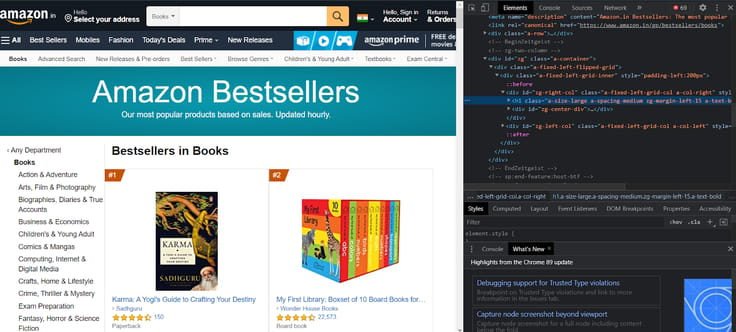
Belirli bir özelliği incelemek istiyorsanız, her birine gidin ve inceleyin. Yazar, kitap adı, derecelendirme, fiyat, puan alan müşteriler için bazı önemli özellikler bulacaksınız.
Kodumuzda, amazon'a kayıtlı olmayan yazarlar için ekstra bulgular uygulamak için iç içe geçmiş if-else ifadelerini kullanacağız.
no_pages = 2
def get_data(pageNo):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
r = requests.get('https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_'+str(pageNo)+'?ie=UTF8&pg='+str(pageNo), headers=headers)#, proxies=proxies)
content = r.content
soup = BeautifulSoup(content)
#print(soup)
alls = []
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-none aok-relative'}):
#print(d)
name = d.find('span', attrs={'class':'zg-text-center-align'})
n = name.find_all('img', alt=True)
#print(n[0]['alt'])
author = d.find('a', attrs={'class':'a-size-small a-link-child'})
rating = d.find('span', attrs={'class':'a-icon-alt'})
users_rated = d.find('a', attrs={'class':'a-size-small a-link-normal'})
price = d.find('span', attrs={'class':'p13n-sc-price'})
all1=[]
if name is not None:
#print(n[0]['alt'])
all1.append(n[0]['alt'])
else:
all1.append("unknown-product")
if author is not None:
#print(author.text)
all1.append(author.text)
elif author is None:
author = d.find('span', attrs={'class':'a-size-small a-color-base'})
if author is not None:
all1.append(author.text)
else:
all1.append('0')
if rating is not None:
#print(rating.text)
all1.append(rating.text)
else:
all1.append('-1')
if users_rated is not None:
#print(price.text)
all1.append(users_rated.text)
else:
all1.append('0')
if price is not None:
#print(price.text)
all1.append(price.text)
else:
all1.append('0')
alls.append(all1)
return allsBu, aşağıdaki işlevleri yerine getirecektir,
for i in range(1, no_pages+1):
results.append(get_data(i))
flatten = lambda l: [item for sublist in l for item in sublist]
df = pd.DataFrame(flatten(results),columns=['Book Name','Author','Rating','Customers_Rated', 'Price'])
df.to_csv('amazon_products.csv', index=False, encoding='utf-8')Şimdi csv dosyasını yükleyeceğiz,
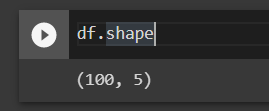
df = pd.read_csv("amazon_products.csv")
df.shapeVeri çerçevesinin şekli, CSV dosyasında 100 satır ve 5 sütun olduğunu gösterir.
Veri kümesinin 5 satırını görelim,
df.head(61)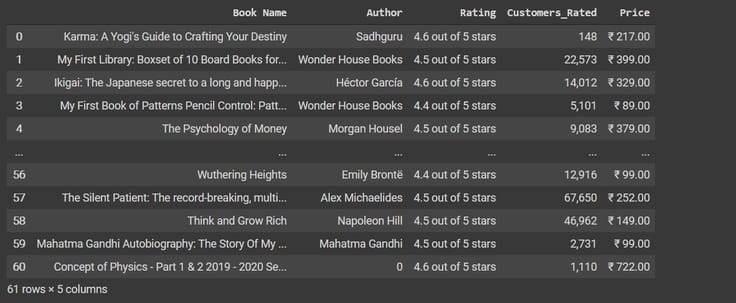
Şimdi rating, customers_rated ve price sütunları üzerinde bazı ön işlemler yapacağız.
df[' Derecelendirme' ] = df['Derecelendirme'].apply(lambda x: x.split()[0])
df[' Derecelendirme'] = pd.to_numeric(df['Derecelendirme'])
df[" Fiyat"] = df["Fiyat"].str.replace('₹', '')
df["Fiyat"] = df["Fiyat"].str.replace(',', '')
df[ 'Fiyat' ] = df['Fiyat'].apply(lambda x: x.split('.')[0])
df['Fiyat'] = df['Fiyat'].astype(int)
df["Customers_Rated"] = df["Customers_Rated"].str.replace(',', '')
df['Customers_Rated'] = pd.to_numeric(df['Customers_Rated'], errors='ignore')
df.head()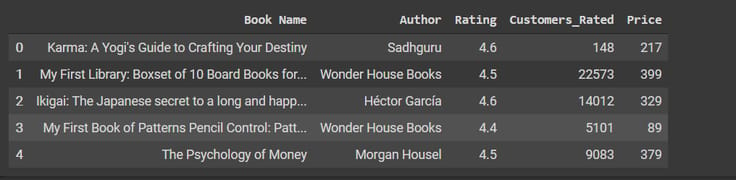
Eğer veri çerçevesi türlerine bir göz atarsak,
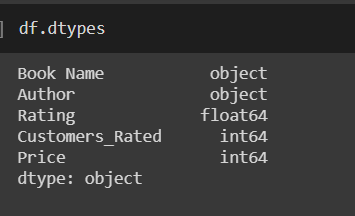
Yukarıdaki çıktıda bazı eksik bilgiler var. Önce NaN'ların sayısını sayacağız ve sonra onları atacağız.
df.replace(str(0), np.nan, inplace=True)
df.replace(0, np.nan, inplace=True)
count_nan = len(df) - df.count()
count_nan
df = df.dropna()Şimdi en yüksek fiyatlı kitaba sahip tüm yazarları tanıyacağız. Onlardan ilk 20'yi tanıyacağız.
data = data.sort_values(['Rating'],axis=0, ascending=False)[:15]
Veri
Şimdi müşteri puanına göre en yüksek puan alan kitapları ve yazarları göreceğiz. 1000'den az yorum alan yazarları ve kitapları filtreleyeceğiz, böylece en ünlü yazarları elde edeceğiz.
data = df[df['Customers_Rated'] > 1000]
data = data.sort_values(['Rating'],axis=0, ascending=False)[:15]
Veri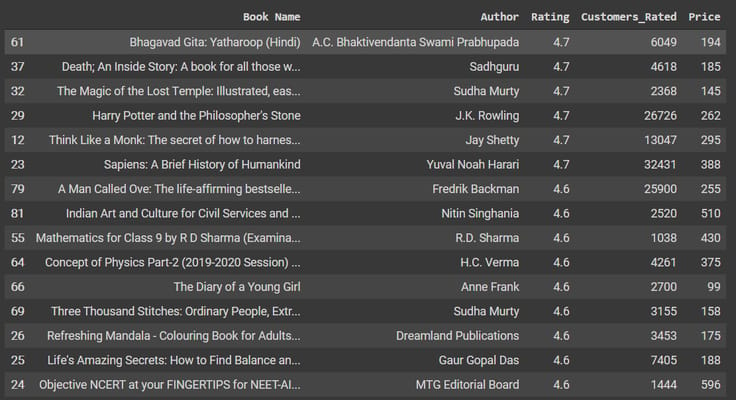
En çok oy alan kitapları görselleştirelim,
p = figure(x_range=data.iloc[:,0], plot_width=800, plot_height=600, title="1000'den Fazla Müşterinin Değerlendirdiği En Çok Oy Alan Kitaplar", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:,0], top=data.iloc[:,2], width=0.9)
p.xgrid.grid_line_color = Yok
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
göster(p)
Ne kadar çok derecelendirme olursa, müşteri güveni o kadar iyi olur. Bu nedenle, müşteriler tarafından en çok oy alan yazarları ve kitapları eklersek daha inandırıcı ve güvenilir olacaktır.
from bokeh.transform import factor_cmap
from bokeh.models import Legend
from bokeh.palettes import Dark2_5 as palette
import itertools
from bokeh.palettes import d3
#colors grafiklerde kullanılabilecek renklerin bir listesini içerir
renkler = itertools.cycle(palet)
palet = d3['Kategori20'][20]
index_cmap = factor_cmap('Yazar', palet=palette,
factors=data["Yazar"])
p = figure(plot_width=700, plot_height=700, title = "En İyi Yazarlar: Puanlama vs Puanlanan Müşteriler")
p.scatter('Rating','Customers_Rated',source=data,fill_alpha=0.6, fill_color=index_cmap,size=20,legend='Author')
p.xaxis.axis_label = 'RATING'
p.yaxis.axis_label = 'CUSTOMERS RATED'
p.legend.location = 'top_left'
göster(p)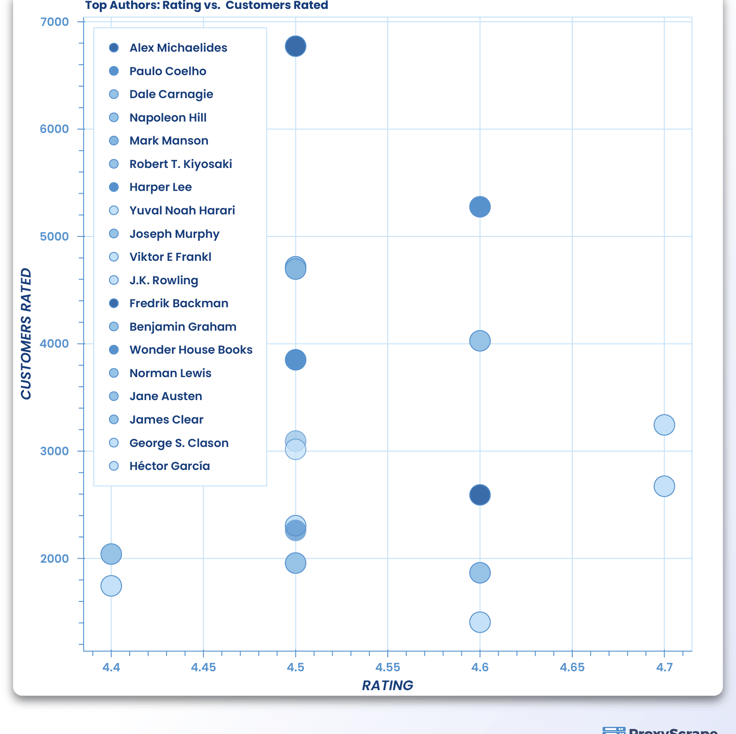
Bu makalede, Amazon'dan veri çıkarmanın çok önemli bir kullanım örneğini ele alarak web kazımanın ne olduğunu gördük. Sadece farklı amazon sayfalarından veri çekmekle kalmadık, aynı zamanda farklı Python kütüphaneleri kullanarak verileri görselleştirdik. Bu makale ileri düzey bir makaleydi ve web kazıma ve veri görselleştirme konusunda yeni olan kişiler için anlaşılması zor olabilir. Onlar için şu adreste bulunan başlangıç paketi makalelerine gitmelerini öneririm ProxyScrape. Web kazıma, işinize ivme kazandırabilecek çok faydalı bir tekniktir. Piyasada bazı harika ücretli araçlar da mevcuttur, ancak kendi kazıyıcınızı kodlayabilecekken neden onlara ödeme yapasınız? Yukarıda yazdığımız kod her web sayfası için çalışmayabilir çünkü sayfa yapısı farklı olabilir. Ancak yukarıdaki kavramları anladıysanız, kodu yapısına göre değiştirerek herhangi bir web sayfasını kazımanız için hiçbir engel yoktur. Umarım bu makale okuyucular için ilginç olmuştur. Hepsi bu kadardı. Bir sonrakinde görüşmek üzere!